ReSID: 推荐原生的语义ID框架——从信息论视角重新思考生成式推荐的Token化
论文: Rethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs
链接: https://arxiv.org/abs/2602.02338
代码: https://github.com/FuCongResearchSquad/ReSID
机构: 中南大学、Shopee、南洋理工大学
时间: 2026年2月
1. 问题背景
基于Semantic ID(SID)的生成式推荐是扩展序列推荐系统的一个有前景的范式。其核心思想是将每个item编码为一组紧凑的离散token序列(如 $[21, 3, 54]$),从而支持自回归解码,而非直接预测数十亿个不相关的原子item ID。
然而,现有的SID方案(如TIGER、LETTER、EAGER等)普遍遵循语义中心(semantic-centric)的设计范式:先用基础模型(LLM/MLLM)学习item embedding,再用通用量化方法(如RQ-VAE、层次化K-Means)将其离散化。这种设计与生成式推荐的目标之间存在根本性的错位,具体体现在两个方面:
1.1 表示提取的错位
基础模型主要优化语义相似性,但语义相似性经常与协同信号冲突。例如,在用户行为中经常共现的物品(如聚会用的零食和气球)在语义或视觉属性上可能相距甚远。即使通过协同信号微调,语义目标和协同目标也会产生相互竞争的几何约束,导致最终的embedding空间既不够语义纯净、也未能与推荐目标最优对齐。
1.2 量化阶段削弱了序列可预测性
现有量化方法的问题可归纳为两类:
- 层次化K-Means:子节点索引在每个父节点下独立、局部地分配。相同的第二级token “1” 在 $(2,1,5)$ 和 $(9,1,7)$ 中可能对应完全不同的语义方向,导致index的语义含义严重依赖其前缀,增加了重建模糊性。
- RQ-VAE / RQ-KMeans:优化重建误差但忽略序列索引间的依赖关系,对自回归建模不友好,产生的SID序列在前缀条件下不确定性高。
2. ReSID框架总览
ReSID从信息论视角重新设计了表示学习和量化两个阶段,完全不依赖LLM,包含两个核心组件:
- FAMAE(Field-Aware Masked Auto-Encoding):学习推荐充分的item表示
- GAOQ(Globally Aligned Orthogonal Quantization):构建紧凑且自回归解码友好的SID
整体仍然遵循三阶段流水线:E-stage(表示学习)→ Q-stage(量化)→ G-stage(生成模型),但每个阶段都进行了面向推荐目标的原生设计。
3. FAMAE:面向推荐的表示学习
3.1 设计动机
FAMAE的核心洞察:结构化特征(structured features)应以原生符号形式直接建模,而非先grounding到文本再用LLM提取。这基于推荐系统中广泛采用的条件独立假设:
\[Y \perp X \mid (F_T, H)\]即给定充分的结构化特征 $F_T$ 和用户历史 $H$,预测目标 $Y$ 与原始item元数据 $X$ 条件独立。
3.2 训练目标
FAMAE使用Transformer编码器,采用字段感知的掩码预测目标进行训练。对于位置 $T$ 的目标item,随机掩码其部分特征字段,模型需要根据剩余字段和用户历史来预测被掩码的字段:
\[\mathcal{L}*{\text{FAMAE}}(\theta) = \mathbb{E}*{\mathcal{M} \sim \pi} \left[ \sum_{k \in \mathcal{M}} \alpha_k \cdot \left( -\log q_{\theta,k}(f_T^{(k)} \mid \mathbf{h}_T) \right) \right]\]其中 $\mathcal{M}$ 是掩码字段集合,$\mathbf{h}_T$ 是Transformer编码器在位置 $T$ 输出的上下文表示。预测分布使用缩放余弦相似度:
\[q_{\theta,k}(f_T^{(k)} \mid \mathbf{h}) = \frac{\exp\left(\mathcal{K}(\mathbf{h}, \mathbf{e}*T^{(k)})\right)}{\sum*{v \in \mathcal{V}_k} \exp\left(\mathcal{K}(\mathbf{h}, \mathbf{e}_v^{(k)})\right)}, \quad \mathcal{K}(\cdot,\cdot) = \sqrt{d} \cdot \cos(\cdot, \cdot)\]与传统的语义自编码不同,这个目标强制字段级别可分离的监督,使表示保留细粒度、任务相关的空间结构。
3.3 信息论解释
FAMAE损失函数具有自然的信息论解释:
命题3.1(预测充分性代理):设掩码策略 $\pi$,字段权重 $\alpha_k \geq 0$,令 $w_k = \alpha_k \Pr_{\mathcal{M} \sim \pi}(k \in \mathcal{M})$,则
\[\sum_{k=1}^{J} w_k I(\mathbf{h}*T; f_T^{(k)}) \geq \sum*{k=1}^{J} w_k H(f_T^{(k)}) - \mathcal{L}_{\text{FAMAE}}(\theta)\]这意味着最小化 $\mathcal{L}_{\text{FAMAE}}$ 会提高表示 $\mathbf{h}_T$ 与目标item特征之间互信息的变分下界。
两个关键含义:
- 预测充分性:学到的表示 $\mathbf{h}_T$ 压缩了 $F_T$ 和 $H$ 的信息,作为下游预测的充分统计量。
- 预测优越性:相比SASRec等使用单标签目标(预测融合后的下一个item表示)的方法,FAMAE通过多字段独立监督保留了更多的互信息。数据处理不等式保证 $I(\mathbf{h}_T; \mathbf{u}_T) \leq I(\mathbf{h}_T; F_T)$,当异构字段通过非可逆算子(如pooling或MLP)融合时等号几乎不成立。
3.4 Item表示提取
上下文表示 $\mathbf{h}_T$ 混杂了用户历史信息,不适合直接用于SID量化。根据数据处理链 $(F_T \rightarrow \mathbf{e}_T \rightarrow \mathbf{h}_T)$,字段级embedding $\mathbf{e}_T$ 保留了至少与 $\mathbf{h}_T$ 等量的信息:$I(\mathbf{e}_T; F_T) \geq I(\mathbf{h}_T; F_T)$,同时不受用户上下文影响。因此最终用于量化的表示为所有字段embedding的拼接:
\[\operatorname{concat}\left( \mathbf{e}_j \right)_{j=1}^{J}\]3.5 Embedding质量的任务感知指标
ReSID提出了两个互补的代理指标来评估E-stage embedding质量,无需端到端重新训练:
- 指标1(协同建模能力):在全字段掩码下的目标item预测准确率——评估embedding是否保留了从用户历史推断目标item所需的预测信息
- 指标2(判别语义与空间结构):在仅掩码item-ID字段下的item-ID预测准确率——评估结构化特征embedding是否具有足够的判别语义信息
实验表明,两个指标都高的表示一致地产生更高质量的SID和更好的下游推荐性能。
4. GAOQ:全局对齐正交量化
4.1 SID量化的理想目标
从信息论视角,一个有效的SID量化器应满足三个需求,形式化为:
\[\min_Q H(\mathbf{z} \mid C) + \mu \sum_l H(\mathbf{z} \mid c_l) + \lambda \sum_l H(c_l \mid C_{(<l)})\] \[\text{s.t. } H(c_l) \approx \log|c_l|\]其中三项分别对应:
- $H(\mathbf{z} \mid C)$:全局重建不确定性(离散瓶颈下的重建失真)
- $H(\mathbf{z} \mid c_l)$:每个code的独立信息含量(单个code应具有高语义贡献)
- $H(c_l \mid C_{(<l)})$:前缀条件不确定性(自回归解码器面临的内在分支不确定性)
- 熵约束保证每层code均匀分布,防止index塌缩
4.2 现有方法的问题分析
RQ-style量化只优化整体重建损失,对自回归解码的本质毫不知情,不约束 $H(c_l \mid C_{(<l)})$。
层次化K-Means的局部索引问题可通过以下分解理解:
\[H(\mathbf{z} \mid c_l) = H(\mathbf{z} \mid c_l, C_{(<l)}) + I(\mathbf{z}; C_{(<l)} \mid c_l)\]局部索引增加了前缀依赖模糊性 $I(\mathbf{z}; C_{(<l)} \mid c_l)$——相同索引在不同前缀下对应不同语义方向。虽然层次化细化可以降低 $H(\mathbf{z} \mid c_l, C_{(<l)})$,但 $I(\mathbf{z}; C_{(<l)} \mid c_l)$ 的增加可能抵消这一增益。
4.3 GAOQ算法设计
GAOQ通过层次化向量量化 + 全局对齐索引联合优化目标函数的三项:
- 降低前缀条件不确定性 $H(c_l \mid C_{(<l)})$:通过层次化向量量化,每一层细化表示空间的划分
- 降低前缀依赖模糊性 $I(\mathbf{z}; C_{(<l)} \mid c_l)$:通过全局对齐码索引实现
全局对齐的具体步骤:
- 平衡聚类:对父节点下的item进行平衡K-Means聚类
- 残差化(中心化):每个子聚类中心减去父节点中心,将跨前缀表示对齐到共同原点
- 锚点构建:构造一组近似正交的全局共享参考方向
- 全局匹配:使用Hungarian匹配将中心化后的子向量与参考方向匹配,确保相同索引在每一层内对应一致的语义方向
- code分配:基于匹配结果分配全局一致的code索引
算法伪代码:
1
2
3
4
5
6
7
8
9
输入: 当前父节点下的item表示集合 Z, 父节点中心 μ, 分支因子 b_l, 锚点数 g_l
输出: 全局对齐的level-l code分配 M
1. 平衡K-Means: 将Z划分为b_l个子簇 {Z_j}, 得到子簇中心 {μ_j}
2. 残差化: μ̃_j ← μ_j - μ
3. 构造g_l个近似正交锚点 A = {a_k}
4. 计算余弦相似度矩阵 W[j,k] = cos(μ̃_j, a_k)
5. Hungarian匹配: 将子簇单射映射到锚点
6. 为每个item分配其所在子簇对应的锚点索引
5. 实验结果
5.1 实验设置
- 数据集:Amazon-2023的10个子集,涵盖从小规模(Musical Instruments, 2.3万item)到大规模(Books, 48.5万item)
- 公平比较:针对以往SID评估中被忽视的混淆因素——SID方法通常利用丰富的item元数据,而序列基线仅用item-ID——论文同时评估了增加结构化特征的基线变体(如SASRec*)
- 评估指标:Recall@5/10, NDCG@5/10, Leave-one-out协议
5.2 主要结果
| 模型类别 | 代表方法 | ReSID相对提升(R@5 / N@5) |
|---|---|---|
| 序列推荐(仅ID) | S³-Rec | +39.56% / +47.18% |
| 序列推荐(+特征) | SASRec* | +13.05% / +29.24% |
| SID生成式 | LETTER(最强基线) | +16.03% / +16.17% |
| SID端到端 | ETEGRec | +47.07% / +50.94% |
核心发现:
- ReSID一致性最优:在所有10个数据集的全部指标上均取得最佳结果,是首个一致优于增加了side information的强item-ID基线的SID方法
- 结构化特征的重要性被低估:SASRec*等增加特征的序列模型常常匹配甚至超越先前的SID方法,说明以往报告的SID提升很大程度来自额外的side information
- 端到端SID学习并非最优:ETEGRec虽然联合优化tokenization和推荐损失,但性能显著低于ReSID,验证了解耦三阶段的设计更稳定
- 协同信号注入至关重要:LETTER和ReSID这类注入协同信号的方法一致优于纯语义的TIGER
5.3 消融实验
| 变体 | 说明 | ReSID相对提升(R@5) |
|---|---|---|
| E1 | LLM embedding + GAOQ | +5.40% |
| E2 | SASRec表示 + GAOQ | +11.05% |
| E3 | BERT4Rec表示 + GAOQ | +12.38% |
| Q1 | FAMAE + RQ-VAE | +5.64% |
| Q2 | FAMAE + 层次化K-Means | +5.15% |
两个组件缺一不可:纯语义embedding、纯协同表示或不做全局对齐的量化都会导致性能下降。
5.4 量化效率
| 数据集 | LETTER | TIGER | ReSID |
|---|---|---|---|
| Arts Crafts & Sewing | 3356分钟 | 224分钟 | 27分钟 |
| Health & Household | 6537分钟 | 372分钟 | 72分钟 |
| Beauty & Personal Care | 7380分钟 | 424分钟 | 96分钟 |
ReSID的量化速度比LETTER快 $77\times - 122\times$,比TIGER快约 $5\times$,因为GAOQ是无参数方法,无需训练量化器。
6. 关键技术洞察
6.1 为什么不用LLM?
ReSID的核心论点是:对于SID构建,推荐充分性比语义丰富性更重要。语义embedding与协同信号存在内在竞争,而离散化过程不可避免地会丢失信息。如果表示以协同信号为主导、语义仅作辅助上下文,那么经过量化后保留的信息更可能是对下游推荐有用的。
FAMAE直接在结构化特征的原生符号空间中学习,训练成本与SASRec等轻量级序列模型相当,而非依赖大型基础模型。
6.2 全局对齐为什么有效?
通过一个直观的例子说明:假设有四个item——花瓶(用户1购买)和气球、零食、餐具(用户2共同购买)。
- 局部索引的层次化K-Means:花瓶和零食可能共享相同的第二级code “1”,而用户2共同购买的三个item获得不同的code,破坏了协同结构
- RQ-VAE:各层code独立分配,层间相关性弱
- GAOQ:通过全局对齐,用户2购买的item共享code “3”,花瓶获得code “1”,在SID中保留了协同关系
6.3 FAMAE的注意力模式
论文通过可视化发现,FAMAE在目标位置的注意力呈现清晰的近因偏差——越近的交互权重越高,这与序列推荐的目标天然对齐。而BERT-style的随机掩码导致注意力分散,缺乏与下一item预测对齐的结构。
7. 局限性与未来方向
- GAOQ缺乏原则性诊断指标:虽然FAMAE有任务感知的embedding质量指标,但GAOQ的量化质量评估仍是开放问题
- SID方法收敛慢:SID-based生成模型的收敛速度比SASRec等item-ID方法慢数十倍
- 三阶段解耦的代价:虽然比端到端更稳定,但三阶段间的信息传递仍然是近似的
8. 总结
ReSID是一个从信息论原理出发、面向推荐目标原生设计的SID框架,其核心贡献在于:
- 重新定义了表示学习目标:用字段级掩码预测替代语义重建,保留推荐充分信息
- 重新定义了量化目标:联合优化重建误差、单code信息量和前缀条件不确定性
- 不依赖LLM:证明了有效的SID构建无需大型基础模型,成本降低两个数量级
- 首次在公平比较下超越强基线:在增加side information的item-ID方法面前,SID方法首次展现一致优势
ReSID对SID领域的重要启示是:与其在语义表示上注入协同信号,不如从一开始就以推荐目标为核心来设计整个pipeline。这一范式转变为大规模推荐系统中的SID构建提供了更高效、更可扩展的解决方案。
参考文献
- Liang, Y., et al. “Rethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs.” arXiv:2602.02338, 2026.
- Rajput, S., et al. “Recommender Systems with Generative Retrieval.” NeurIPS 2023.
- Wang, W., et al. “LETTER: Learnable Item Tokenization for Generative Recommendation.” CIKM 2024.
- Wang, Y., et al. “EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration.” KDD 2024.
- Xiao, L., et al. “UNGER: Generative Recommendation with a Unified Code via Semantic and Collaborative Integration.” ACM TOIS, 2025.
- Liu, E., et al. “Generative Recommender with End-to-End Learnable Item Tokenization.” SIGIR 2025.
- Kang, W.-C., et al. “Self-Attentive Sequential Recommendation.” ICDM 2018.
- Sun, F., et al. “BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer.” CIKM 2019.
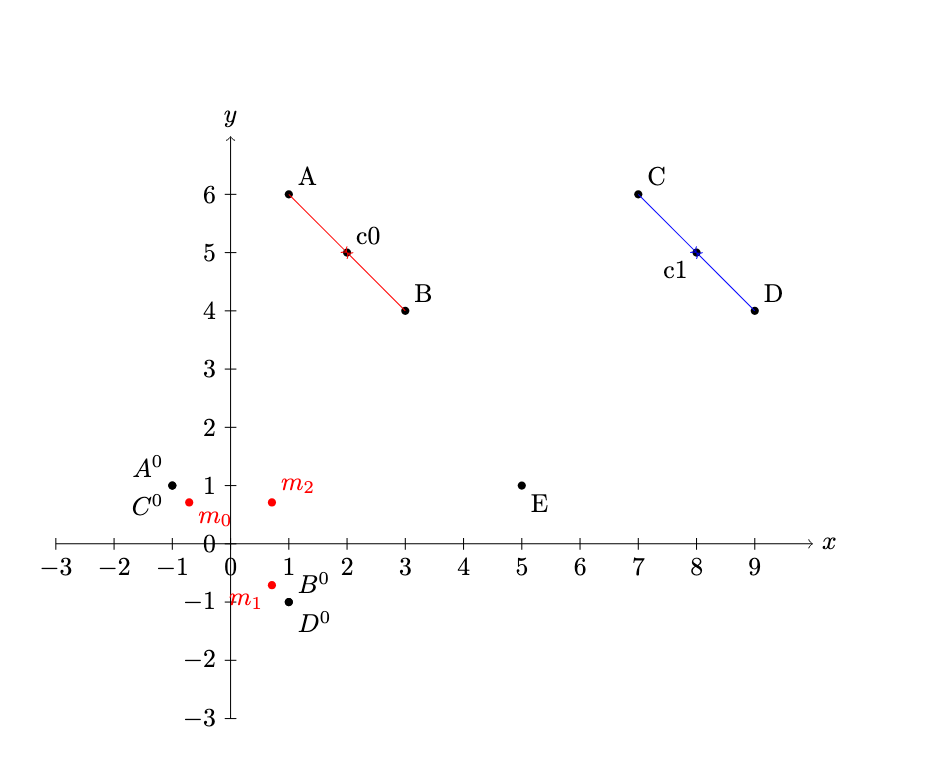
下面用一个完整的具体例子走一遍 GAOQ 的全过程。
设定
5 个 item,每个用 2 维向量表示
量化为 2 级 SID,每级取值范围 {0, 1, 2}(分支因子 $b=3$)
| Item | 向量 |
|---|---|
| A | [1, 6] |
| B | [3, 4] |
| C | [7, 6] |
| D | [9, 4] |
| E | [5, 1] |
第一级:平衡 K-Means(和普通方法一样)
对全部 5 个 item 做平衡 K-Means,分成 3 簇:
| 簇 | Item | 簇中心 |
|---|---|---|
| 簇 0 | A[1,6], B[3,4] | [2, 5] |
| 簇 1 | C[7,6], D[9,4] | [8, 5] |
| 簇 2 | E[5,1] | [5, 1] |
第一级 code 分配:A→0, B→0, C→1, D→1, E→2
第一级是根节点,全局唯一,不需要对齐。
第二级:先看普通层次化 K-Means 会怎么做
每个父簇内部各自独立做 K-Means:
簇 0 内部(A 和 B):随意分配编号
| Item | 残差方向 | 分配编号 |
|---|---|---|
| A[1,6] | 偏左上 | 0 |
| B[3,4] | 偏右下 | 1 |
簇 1 内部(C 和 D):也随意分配编号
| Item | 残差方向 | 分配编号 |
|---|---|---|
| C[7,6] | 偏左上 | 1 |
| D[9,4] | 偏右下 | 0 |
最终结果:
| Item | SID | 第二级编号的含义 |
|---|---|---|
| A | (0, 0) | 0 = 左上 |
| B | (0, 1) | 1 = 右下 |
| C | (1, 1) | 1 = 左上 |
| D | (1, 0) | 0 = 右下 |
问题暴露了:编号 “0” 在簇 0 下代表”左上”,在簇 1 下代表”右下”。生成模型看到同一个 token “0”,含义却相反。
第二级:GAOQ 怎么做
步骤一:平衡聚类(同上)
每个父簇内部 K-Means 得到子簇中心,这步和普通方法一样。
1
2
簇0: A的子中心=[1,6], B的子中心=[3,4]
簇1: C的子中心=[7,6], D的子中心=[9,4]
步骤二:残差化(中心化)
每个子中心 减去父簇中心,统一到以原点为参考的坐标系:
簇 0(父中心 [2, 5]):
\[\tilde{\mu}_A = [1,6] - [2,5] = [-1, +1] \quad \text{(指向左上)}\] \[\tilde{\mu}_B = [3,4] - [2,5] = [+1, -1] \quad \text{(指向右下)}\]簇 1(父中心 [8, 5]):
\[\tilde{\mu}_C = [7,6] - [8,5] = [-1, +1] \quad \text{(指向左上)}\] \[\tilde{\mu}_D = [9,4] - [8,5] = [+1, -1] \quad \text{(指向右下)}\]中心化之后,可以看到 A 和 C 的残差方向相同,B 和 D 的残差方向相同。这就是对齐的基础。
步骤三:构造全局锚点
生成 3 个近似正交的参考方向(因为每级取值范围 0-2,需要 3 个锚点),所有父簇共享:
| 锚点 | 方向 | 语义含义 |
|---|---|---|
| 锚点 0 | [-0.71, +0.71] | “左上” |
| 锚点 1 | [+0.71, -0.71] | “右下” |
| 锚点 2 | [+0.71, +0.71] | “右上” |
步骤四:Hungarian 匹配
计算每个父簇内子中心残差与所有锚点的余弦相似度,然后做一对一最优匹配。
簇 0 的匹配:
| 锚点 0 (左上) | 锚点 1 (右下) | 锚点 2 (右上) | |
|---|---|---|---|
| A 残差 [-1,+1] | 1.0 | -1.0 | 0.0 |
| B 残差 [+1,-1] | -1.0 | 1.0 | 0.0 |
Hungarian 最优匹配:A → 锚点 0(编号 0),B → 锚点 1(编号 1)
簇 1 的匹配:
| 锚点 0 (左上) | 锚点 1 (右下) | 锚点 2 (右上) | |
|---|---|---|---|
| C 残差 [-1,+1] | 1.0 | -1.0 | 0.0 |
| D 残差 [+1,-1] | -1.0 | 1.0 | 0.0 |
Hungarian 最优匹配:C → 锚点 0(编号 0),D → 锚点 1(编号 1)
簇 2:只有 E 一个 item,直接匹配到最近锚点即可。
最终对比
| Item | 普通层次化 K-Means | GAOQ |
|---|---|---|
| A | (0, 0) — “0”=左上 | (0, 0) — “0”=左上 |
| B | (0, 1) — “1”=右下 | (0, 1) — “1”=右下 |
| C | (1, 1) — “1”=左上 | (1, 0) — “0”=左上 |
| D | (1, 0) — “0”=右下 | (1, 1) — “1”=右下 |
| E | (2, 0) | (2, 0) |
GAOQ 的结果中,编号 0 在任何父簇下都代表”左上”方向,编号 1 都代表”右下”方向。生成模型学到的第二级 token embedding 可以跨所有前缀复用,不再需要记忆”在前缀 0 下编号 0 是什么意思、在前缀 1 下编号 0 又是什么意思”。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
\documentclass{article}
\usepackage{tikz}
\begin{document}
\begin{tikzpicture}[scale=0.8]
% 绘制坐标系
\draw[->] (-3, 0) -- (10, 0) node[right] {$x$};
\draw[->] (0, -3) -- (0, 7) node[above] {$y$};
% 标记坐标轴刻度
\foreach \x in {-3,-2,...,9} \draw (\x, 0.1) -- (\x, -0.1) node[below] {$\x$};
\foreach \y in {-3,-2,...,6} \draw (0.1, \y) -- (-0.1, \y) node[left] {$\y$};
% 绘制点并标注
\fill (1, 6) circle (2pt) node[above right] {A};
\fill (3, 4) circle (2pt) node[above right] {B};
\fill (7, 6) circle (2pt) node[above right] {C};
\fill (9, 4) circle (2pt) node[above right] {D};
\fill (5, 1) circle (2pt) node[below right] {E};
\fill (2, 5) circle (2pt) node[above right] {c0};
\fill (8, 5) circle (2pt) node[below left] {c1};
\fill (-1, 1) circle (2pt) node[above left] {$A^0$};
\fill (1, -1) circle (2pt) node[above right] {$B^0$};
\fill (-1, 1) circle (2pt) node[below left] {$C^0$};
\fill (1, -1) circle (2pt) node[below right] {$D^0$};
\fill[red] (-0.71, 0.71) circle (2pt) node[below right] {$m_0$};
\fill[red] (0.71, -0.71) circle (2pt) node[below left] {$m_1$};
\fill[red] (0.71, 0.71) circle (2pt) node[above right] {$m_2$};
% 绘制从Item到聚类中心的连线
\draw[->, red] (1, 6) -- (2, 5);
\draw[->, red] (3, 4) -- (2, 5);
\draw[->, blue] (7, 6) -- (8, 5);
\draw[->, blue] (9, 4) -- (8, 5);
\end{tikzpicture}
\end{document}