学习率衰减如何浪费课程学习中的优质数据
论文: How Learning Rate Decay Wastes Your Best Data in Curriculum-Based LLM Pretraining
链接: https://arxiv.org/abs/2511.18903
机构: 清华大学、鹏城实验室
时间: 2025 年 11 月(arXiv v3 更新于 2026 年 5 月)
1. 问题背景
大语言模型预训练的数据侧优化,过去数年主要围绕两条主线展开:数据策展(data curation)与数据排序(data ordering)。
前者通过启发式过滤、模型打分、基于分数的子集选择等手段,在训练开始前把低质量样本挡在门外,提升混合语料的整体质量——DCLM、FineWeb、Nemotron-CC 等流水线都是这一思路的代表。后者则试图在不改变样本集合的前提下,通过课程学习(curriculum learning)按质量从低到高依次喂给模型,让高质量数据出现在训练后期,以缓解灾难性遗忘、更充分地吸收高价值信号。实例级排序课程在 QuRating、PDS、DCLM fastText 等质量指标已经相当成熟的情况下,仍被多篇工作报告为收益有限甚至令人困惑(例如 Wettig et al. 发现反向课程有时也能小幅提升)。
与此同时,学习率调度(LR schedule)几乎被默认为与数据顺序无关的独立超参:cosine decay、Warmup-Stable-Decay(WSD)等 schedule 都在「均匀随机打乱数据」的设定下调优,最终 LR 往往衰减到接近零($10^{-5}$ 量级)。多阶段 mid-training(先大规模 web 数据、后切高质量子集)虽被广泛采用(OLMo 2、Phi-4、LongCat-Flash 等),但实例级「全局按分数升序」与标准 LR decay 如何相互作用,此前缺乏系统分析。
本文的核心论断可以概括为一句话:升序数据课程把最好的数据放在训练末尾,而标准 LR decay 恰恰在末尾把更新步长压到最小——二者在时间上错位,导致高质量数据的梯度信号被「饿死」。作者团队(Luo、Sun、Wen 等,通讯作者 Kaifeng Lyu、Wenguang Chen)在 1.5B 参数、30B token 的 DCLM 规模上验证:恒定 LR 下升序课程显著优于均匀打乱;一旦换成 WSD 或 cosine,课程优势大幅缩水甚至消失。进一步提出 CMA(Curriculum Model Averaging) 与 CDMA 等协同设计,在无需额外数据精炼的前提下,标准 benchmark 平均准确率相对「WSD + Uniform」基线提升约 1.64%。
四点主要贡献:
- 揭示 数据 schedule 与 LR schedule 的不兼容性,解释既有课程学习研究收益微弱的常见原因;
- 提出 适度 LR decay(终态 LR 约为 peak 的 $1/3$)作为简单缓解手段,并刻画 uniform 与 curriculum 对终态 LR 的不同最优区间;
- 提出 CMA:用恒定 LR + 权重平均(EMA/SMA)替代 decay,与升序课程产生协同,mid-training 场景 Core benchmark 可提升 2%+;
- 提出 CDMA:适度 decay + 权重平均的联合策略,在 3.2B、150B+ token 持续预训练上验证可扩展性。
与微软 DELT(数据效力)工作的关系值得单独说明:DELT 关注 如何排序/折叠数据(LQS 评分、Folding Ordering);本文关注 排序策略必须与 LR/权重平均协同设计。DELT 的 Folding 旨在把高质量数据分散到全程以规避 LR 衰减——本文则从优化动力学角度证明:在正确 regime 下,端到端升序 + 不衰减(或适度衰减)+ 模型平均,可以比 Folding 更简洁且更稳健(见第 6 节与 DELT 的对比讨论)。
2. 核心机制:LR 作为隐式样本权重
2.1 梯度分解与双重角色
论文第 2 节给出分析框架。设第 $t$ 步参数更新为(与 Adam 等自适应优化器无关,LR 仍主导步长量级):
\[\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta_t \boldsymbol{g}_t\]其中 $\eta_t$ 为学习率,$\boldsymbol{g}_t$ 为随机梯度。将 $\boldsymbol{g}_t$ 分解为信号分量 $\mathbb{E}[\boldsymbol{g}_t]$(指向稳定改进方向)与噪声分量 $\boldsymbol{\epsilon}_t$。衰减的 $\eta_t$ 同时:
- 降低噪声:稳定训练、抑制震荡;
- 缩小信号方向上的有效步长:减缓沿 $\mathbb{E}[\boldsymbol{g}_t]$ 的进展。
在升序质量课程中,高质量样本被刻意安排在训练后期;而 WSD/cosine 等常规 schedule 在后期把 $\eta_t$ 压到最小。于是:最有价值的样本获得了最小的有效更新权重——LR schedule 成为每条样本的隐式重要性权重,与数据课程的设计意图直接冲突。
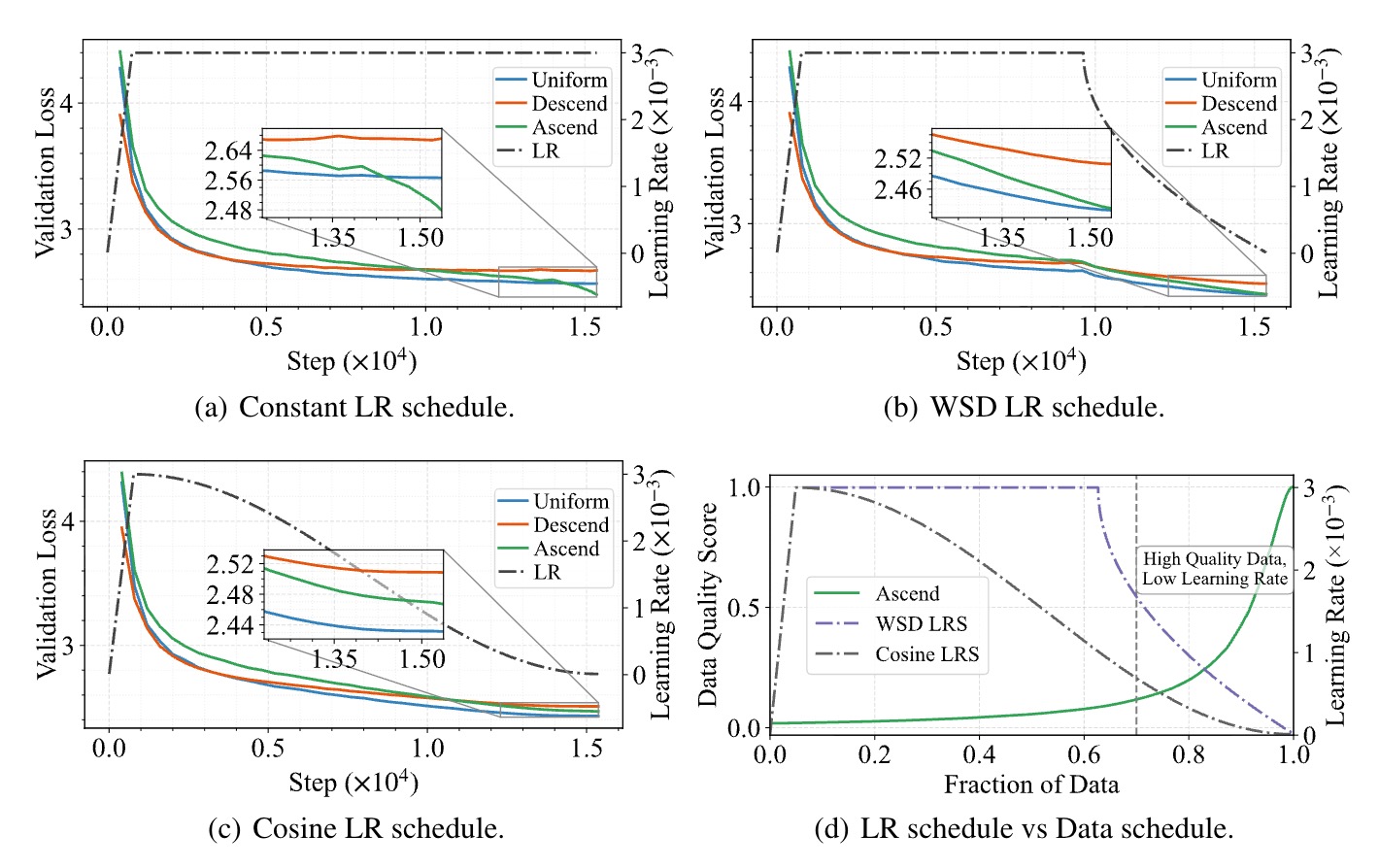
图 1(论文 Fig. 1)直观展示了时间轴上的错位:数据课程把 DCLM 高分样本放在后段,LR decay 在同一阶段把 $\eta$ 拉低;恒定 LR 下升序曲线明显低于 Uniform,WSD/cosine 下 Ascend 与 Uniform 的差距大幅收窄。
2.2 与「数据折叠(Folding)」的对比
DELT、Zhang et al. 等工作提出的 Folding:把数据集分成若干 stage(本文复现采用 Dai et al. 认定最优的 3 折),段内按质量排序,使高质量样本更早出现,以减轻「末期 LR 过小」的影响。本文在 1.5B + cosine 下复现:Folding 略优于简单升序,但仍不及 Uniform 基线;而在恒定 LR 下,简单端到端升序反而优于 Folding。
Folding 跨尺度不鲁棒的直接证据(0.5B,Table 12):在低 peak LR($1\times10^{-4}$)下,复现 Dai et al. 的观察——Folding(Avg. 39.22)> 简单升序(38.99)> Uniform(38.75);但把 peak LR 提到 $3\times10^{-3}$ 后优势反转:简单升序(45.20)反而 > Folding(44.77),且高 LR 整体性能(45.x)远超低 LR(38.x)。这说明 Folding 的收益很可能只是对「错误的低 LR regime」的补偿,而非课程本身的本质优势——一旦把 LR 调到正确量级,Folding 的「分散高质量数据以规避末期低 LR」这一动机就失去了立足点。这与全文「课程必须与 LR/WA 协同设计」的主张一脉相承。
2.3 损失地貌(River-Valley)解释
作者借用 Wen et al. (2025) 的 river-valley 模型:优化轨迹沿信号方向(河床)缓慢下降,沿噪声方向(谷底横向)剧烈震荡。数据质量影响梯度信噪比——高质量数据 → 更稳、更强的信号方向。图 4 对比三种策略在损失–噪声坐标平面上的末段轨迹投影(论文 Fig. 4):
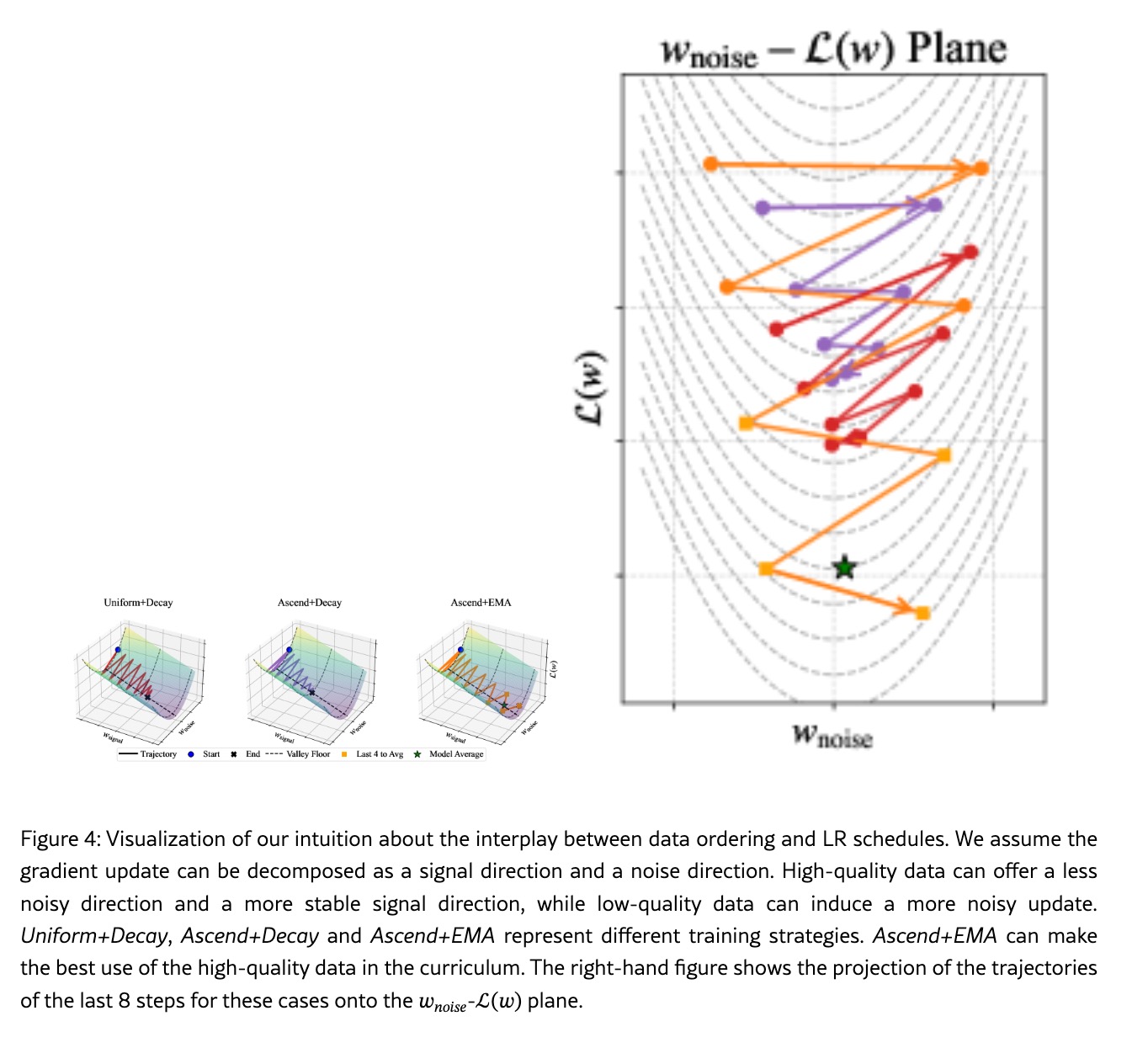
| 策略 | 行为 |
|---|---|
| Uniform + Decay | 全程噪声水平较一致;末期 decay 降噪但也减慢沿信号方向的推进 |
| Ascend + Decay | 早期高噪声;末期虽遇高质量数据,但 LR 过小,无法沿强信号方向大步前进 |
| Ascend + EMA | 末期保持较大更新幅度;高质量数据提供清晰梯度;EMA 在噪声方向做平均以稳态 |
这与 Dremov et al. 对 WSD cooldown 阶段 bias-variance 的分析一致:cooldown 的「降噪」与课程「末段强信号」在目标上存在张力。
3. 实验设定与「LR–课程」耦合的实证
3.1 主实验配置
| 项目 | 设定 |
|---|---|
| 框架 | DataComp-LM (DCLM) 1B-1x scale |
| 模型 | Qwen2.5-1.5B(28 层、GQA、SwiGLU,hidden 1536) |
| 数据 | DCLM-Baseline 30B token 子集;质量分数:DCLM fastText |
| 序列长度 / batch | 4096 / 512 |
| Peak LR | $3\times10^{-3}$(经适度调优) |
| 默认终态 LR(WSD) | $1\times10^{-5}$(对齐 uniform 最优文献) |
| 优化器 | AdamW,$\beta_1=0.9$,$\beta_2=0.95$,wd=0.1,grad clip=1.0 |
| 验证集 | 从 held-out 分区取 DCLM 分数最高的 10 万文档 |
| 下游评测 | OLMES:MMLU、ARC-e/c、CSQA、OBQA、PIQA、SIQA、WinoGrande;Core = 前四项均值(Heineman et al. 高信噪比子集) |
数据 schedule:Uniform(随机)、Ascend(DCLM 分数升序)、Descend(反向,作对照)。LR schedule:Constant(warmup 后恒定)、WSD(1-sqrt decay,decay 阶段约 15%–20% 总步数)、Cosine。
3.2 关键发现一:恒定 LR 下课程非常有效
Figure 1(a):升序课程验证 loss 显著低于 Uniform,收敛更快;降序课程 loss 持续上升(分布逐渐偏离高质量验证集)。PreSelect 分数下复现相同趋势(Appendix Fig. 8)。这证明 质量指标本身有足够信号——问题不在打分不准,而在与 LR 的耦合。
3.3 关键发现二:decay 越激进,课程优势越小
Figure 2 系统 ablate WSD 的 decay 步数占比(37% / 18% / 6% / 0%)与 终态 LR($10^{-5}$ ~ $3\times10^{-3}$)。度量验证 loss 差值 $\mathcal{L}_{\mathrm{Uniform}}-\mathcal{L}_{\mathrm{Ascend}}$(差值越大表示课程优势越明显):
- decay 阶段越长、终态 LR 越小 → 课程相对收益单调缩小;
- 与 uniform 相比,uniform 侧更受益于激进 decay(验证 loss 更低),课程侧则相反。
实验设计合理性:固定模型与 token 预算,只动 schedule 与排序,能 isolate 耦合效应;验证集专门从高 DCLM 分文档抽取,与升序课程目标一致,避免「课程优化目标与评估不一致」的混淆。局限在于:仅 30B token、单 epoch 风格——与工业万亿 token 训练仍有尺度差距(作者在 3.2B 持续预训练上做了部分外推,见 5.5 节)。
4. 方法详解
4.1 学习率 schedule 的形式化
Cosine(全程衰减):
\[\eta(t) = \eta_0 \left( \frac{1+\alpha}{2} + \frac{1-\alpha}{2} \cos\left(\frac{\pi t}{T}\right) \right)\]- $\eta_0$:peak LR;$T$:总步数;$\alpha$:终态 LR 与 peak 之比。
WSD:线性 warmup → 恒定 plateau($\eta_0$)→ 1-sqrt decay:
\[\eta(t) = \eta_0 \left(1 - \sqrt{r(t)}\right) + \eta_T \sqrt{r(t)}, \quad r(t) = \frac{t - t_{\text{decay}}}{T - t_{\text{decay}}}\]- decay 起始步与 $\eta_T$(终态 LR)。论文对比 1-sqrt 与 $(1-r)^{1.5}$,二者接近,主实验采用 1-sqrt(与 Hägele、Tian 等一致)。
WSMD(Warmup-Stable-Moderate Decay):理论分析中把 WSD 的 decay 窗口从 $\Theta(M)$ 缩短为 $\Theta(M^{2/3})$,终态 LR 更大,用于证明「适度 decay 可打破 $\Omega(L^2)$ 障碍」(见第 5 节)。
4.2 缓解方案 A:适度 LR decay
对 Uniform 与 Ascend 分别扫描终态 LR(Figure 5):
- Uniform:最优终态 LR 接近 0($10^{-5}$ 量级),与 Li et al. (2025b) 等「可预测 scale」结论一致;
- Ascend:最优终态 LR 约在 $10^{-3}$,约为 peak 的 $1/3$;过低终态 LR 时课程甚至跑不过 Uniform+WSD。
机制:适度 decay 在「利用课程末段高质量数据」与「一定降噪」之间折中。论文指出:课程相对收益随终态 LR 升高可能仍增加,但绝对性能在终态 LR 接近 peak 时会下降——需联合看绝对分数与相对增益。
4.3 缓解方案 B:CMA(Curriculum Model Averaging)
核心思想:用模型平均替代 LR decay 的「稳态」功能,训练全程保持恒定 peak LR,使末段高质量数据仍有大步长更新。
算法流程(Algorithm 1):
- 离线排序:按质量分数对全量数据升序(Spark 一次性,分数常与过滤流水线共用,无额外标注成本);
- Warmup + Constant LR 训练:按排序顺序取 batch,末段保存 $k$ 个 checkpoint(默认 $k=6$,间隔 $s$ 步);
- 权重平均:默认 EMA,$\alpha=0.2$,对最近 checkpoint 赋更高权重。
三种平均方式(Appendix B):
| 方法 | 公式/含义 | 与课程的关系 |
|---|---|---|
| SMA | $M_{\text{avg}}=\frac{1}{N}\sum_{i=1}^{N}M_i$,末 $N$ 个 checkpoint 均匀加权 | 均匀权重 |
| EMA | 递推 $M_{\text{avg}}^{(i)}=\alpha M_i+(1-\alpha)M_{\text{avg}}^{(i-1)}$,$\alpha=0.2$ | 近期(高质量段)checkpoint 权重指数级更大 |
| WMA | $M_{\text{avg}}=\sum_i w_i M_i$,$w_i\propto\eta(t_i)-\eta(t_{i+1})$ | 权重正比于相邻 checkpoint 的 LR 下降量 |
WMA 为何不适合升序课程:WMA 源自 Tian et al. (WSM) 的「用 WA 模拟 LR decay」思路——其权重 $w_i\propto\eta(t_i)-\eta(t_{i+1})$ 正比于该区间的 LR 降幅。在标准 decay 中 LR 后期降得最快,故 WMA 把最大权重压在偏早的 checkpoint上(权重随训练递减)。但升序课程恰恰要求「越晚(质量越高)的 checkpoint 权重越大」,二者方向相反。重要实证(Table 1):升序课程下 EMA/SMA(对后期 checkpoint 赋非递减权重)的 Core 达 46.95/47.02,明显优于 WMA 的 46.49——验证了「checkpoint 权重应与数据 schedule 对齐」这一设计原则。WMA 仅在 Uniform+Const 下与 decay 等价,不适合课程。
Table 1 主结果(相对 WSD+Uniform 基线):
| 配置 | Core | Avg. | 解读 |
|---|---|---|---|
| Cos + Uniform | 44.31 (−1.90) | 49.13 | 弱基线 |
| WSD + Uniform | 46.21 | 50.56 | 强基线 |
| WSD + Ascend | 45.45 (−0.76) | 50.34 | 课程 + 标准 decay ≈ 无效 |
| EMA + Ascend + Const | 46.95 (+0.74) | 50.95 (+0.39) | CMA 超过 WSD+Uniform |
| SMA + Ascend + Const | 47.02 (+0.81) | 50.94 | 最佳 Core 之一 |
同时:EMA+Uniform+Const 不及 WSD+Uniform——说明 模型平均不能单独替代 decay,必须与课程联用。
4.4 CDMA:适度 decay + 模型平均
CDMA = Curriculum + Moderate LR Decay + Model Averaging。在 WSD 终态 LR 从 $10^{-5}$ 扫到 $10^{-3}$ 后,再对末 checkpoint 做 EMA。Figure 5 显示存在 Optimal Regime(moderate 终态 LR + EMA),稳定优于 Previous Focus Regime(激进 decay、无 WA、无课程)。Mid-training 下最佳组合相对 Uniform+WSD(终态 $10^{-5}$)平均 benchmark +1.68%。
WSMD + WA 的直接实证(Appendix Table 5):理论上 WSMD(适度 decay)与 SWA 同阶,论文也给出了对应的下游实测,进一步把「CDMA 优于纯 CMA」坐实——基线为 WSD+Ascend(无 WA):
| 配置 | Core | Avg. | 解读 |
|---|---|---|---|
| WSD + Ascend(基线) | 43.40 | 48.88 | 课程 + 激进 decay |
| EMA + Ascend + Const(纯 CMA) | 44.94 (+1.54) | 48.67 (−0.21) | Core 涨但 Avg. 略降 |
| EMA + Ascend + WSMD | 45.77 (+2.37) | 49.38 (+0.50) | 适度 decay 叠加 EMA |
| SMA + Ascend + WSMD | 45.90 (+2.50) | 49.51 (+0.63) | 最佳组合 |
关键观察:纯 CMA(恒定 LR + EMA)在 Core 上已有 +1.54,但 Avg. 反而 −0.21(PIQA、Wino. 等高质数据不敏感任务受恒定 LR 末段噪声拖累);一旦改为 WSMD(适度 decay)+ EMA/SMA,Core 与 Avg. 同时显著提升(+2.50 / +0.63)。这说明:恒定 LR 把信号轴步长保到最大,但完全不降噪在部分任务上有代价;适度 decay 提供「最后一点降噪」,与 EMA 的平均降噪叠加,恰好补上 CMA 的短板——正是 §5 理论中「WSMD 与 SWA 殊途同归、二者结合更稳」的实证落点。
实践指南(论文归纳):
- 课程预训练:终态 LR 显著高于 uniform 最优(本文约 $10^{-3}$ vs $10^{-5}$);
- 叠加 EMA/SMA($\alpha \approx 0.2$,末 6 个 checkpoint)可进一步提升稳定性;
- 超参若在 uniform 上 tune 后直接用于课程,会系统性低估课程收益。
4.5 Mid-training 两阶段设定
模拟工业 mid-training(Table 2):
- Phase 1(29B tokens):WebOrganizer(未经模型过滤,偏低质);
- Phase 2(5B tokens):DCLM-Baseline top 10%(高质),LR decay 至 $10^{-5}$。
数据顺序记法:U,U / U,A / A,A / A-T(两阶段合并全局排序)。
| 配置 | Core | Avg. |
|---|---|---|
| WSD + U,U | 41.61 | 47.49 |
| WSD + A-T | 42.73 (+1.12) | 48.01 |
| EMA + A,A + Const | 43.61 (+2.00) | 48.69 (+1.20) |
| EMA + A-T + Const | 43.82 (+2.21) | 48.69 (+1.20) |
解读:
- CMA 在 mid-training 增益更大——高质量数据稀缺时,每样本信号更珍贵,末段大步长吸收高质数据回报更高;
- 仅对第二阶段做课程(U,A)不够;第一阶段升序(A,A)也有益——推测可对「漏网低质样本」利用遗忘机制(推测基于论文 §3.3 讨论);
- 分 phase 排序(A,A) 接近全局 A-T,降低全局排序的工程成本。
5. 理论模型(第 4 节)
论文在二维二次损失上给出与实证一致的可证明分离,帮助理解「为何 SWA/WSMD 能赢、实用 WSD 不能」。
5.1 问题设定
\[\mathcal{L}(\boldsymbol{w}) = \frac{1}{2}\|\boldsymbol{w} - \boldsymbol{w}^\ast\|_2^2, \quad \boldsymbol{w}^\ast = \mathbf{0}, \quad \boldsymbol{w}_0 = (L, 0)\]每个样本 loss 为 $\ell_t(\boldsymbol{w})=\lVert\boldsymbol{w}-\boldsymbol{x}_t\rVert_2^2$。数据点 $\boldsymbol{x}^{(i)}$ 在信号轴取 $x_1^{(i)}=(i-1)d$,在噪声轴服从 $\mathrm{Uniform}(-L,L)$,且 $d=L/M$。升序课程:第 $t$ 步采样 $\boldsymbol{x}^{(M-t+1)}$(质量随时间升高)。记期望损失 $\bar{\mathcal{L}}(M;E)=\mathbb{E}[\mathcal{L}(\boldsymbol{w})]$,期望对 SGD 随机性与数据采样取平均。
5.2 四个情形的界限
| 情形 | 期望损失阶 | 含义 |
|---|---|---|
| Uniform 采样 + 任意 LR | $\Omega(L^2)$ | 信号轴上随机采样,期望停在数据均值附近,无法逼近原点 |
| 升序 + 实用 WSD(末 10% 步 decay) | $\Theta(L^2)$ | 与 uniform 同阶,课程无法打破障碍 |
| 升序 + WSMD(decay 窗口 $\Theta(M^{2/3})$) | $\Theta(M^{-2/3} L^2)$ | 适度 decay,末段仍有一定 $\eta$,打破 $\Omega(L^2)$ |
| 升序 + 恒定 LR + SWA | $\tilde{O}(M^{-2/3} L^2)$ | 信号轴积累足够位移;噪声轴由平均降噪 |
下面逐一展开四个情形的关键推导(完整证明见 Appendix F,这里抽取每一步的物理直觉与代数骨架)。所有情形的共同起点是:在该二次损失下,SGD 的单步更新等价于「当前参数」与「采样点」的凸组合——
\[\boldsymbol{w}_t = (1-\eta_t)\boldsymbol{w}_{t-1} + \eta_t \boldsymbol{x}_t\]即每一步都把参数朝当前样本拉近 $\eta_t$ 比例。整条轨迹因此是历史所有样本的带权移动平均,权重由 LR schedule 决定——这正是「LR = 隐式样本权重」论断的数学具现。
情形一:Uniform 采样(Lemma F.1,$\Omega(L^2)$ 下界)
信号轴 $x_1$ 上,对更新取期望:$\mathbb{E}[w_t^{(1)}] = (1-\eta_t)\mathbb{E}[w_{t-1}^{(1)}] + \eta_t\cdot\frac{(M-1)d}{2}$,其中 $\frac{(M-1)d}{2}$ 是全体样本信号坐标的均值($x_1^{(i)}=(i-1)d$ 在 $i$ 上均匀采样的期望)。由归纳法可证 $\mathbb{E}[w_t^{(1)}]\ge\frac{(M-1)d}{2}$ 恒成立,于是 $\mathbb{E}[\mathcal{L}]\ge(\mathbb{E}[w_t^{(1)}])^2=\Theta(L^2)$。直觉:随机打乱时每一步的「目标」都是整个数据集的均值(位于 $L/2$ 附近),无论 LR 如何调度,期望意义上参数被钉死在数据均值,永远无法逼近原点 $\boldsymbol{w}^\ast=\mathbf{0}$。这条下界对任意 LR schedule 都成立——这正解释了为何 uniform 设定下「怎么调 LR 都救不回信号轴的系统性偏差」,只能靠课程改变采样顺序。
情形二、三:升序 + 广义 WSD(Lemma F.2,统一刻画)
把 WSD 的 decay 窗口长度参数化为 $T_0$:前 $M-T_0$ 步保持 $\eta_0=\frac{1}{2}$,末 $T_0$ 步令 $\eta_t=\frac{1}{t-(M-T_0)}$(调和衰减)。通过展开递推式并利用裂项积 $\prod_{k=2}^{T_0}\frac{k-1}{k}=\frac{1}{T_0}$,可得末态信号坐标
\[w_M^{(1)} = \Theta(T_0 d) + \Theta\!\left(\frac{d}{T_0}\right) = \Theta(T_0 d)\]而噪声轴因末 $T_0$ 个独立噪声被 $\frac{1}{T_0}$ 加权平均,方差为 $\Theta(L^2/T_0)$。合并得到统一的期望损失:
\[\bar{\mathcal{L}}(M; E) = \tilde{\Theta}\!\left(T_0^2 d^2 + \frac{L^2}{T_0}\right), \qquad d=\frac{L}{M}\]这条公式是整个理论的核心权衡,两项含义相反:
- 第一项 $T_0^2 d^2 = T_0^2 L^2/M^2$(信号轴偏差):decay 窗口越长($T_0$ 越大),越早进入小 LR 区,末段高信号样本到来时步长已被压扁,沿信号轴推进不足,偏差越大;
- 第二项 $L^2/T_0$(噪声轴方差):decay 窗口越长,参与平均的噪声样本越多,降噪越充分,方差越小。
对 $T_0$ 求极小($2T_0 L^2/M^2 = L^2/T_0^2 \Rightarrow T_0^3=\Theta(M^2)$)给出最优窗口 $T_0=\Theta(M^{2/3})$,此时两项相等,均为 $\Theta(M^{-2/3}L^2)$。由此:
- 情形二(实用 WSD):$T_0=\lfloor 0.1M\rfloor=\Theta(M)$,远大于最优窗口,第一项 $T_0^2 d^2=\Theta(L^2)$ 主导 → $\bar{\mathcal{L}}=\Theta(L^2)$,与 uniform 同阶,课程白做。这就是「10% decay 这种业界惯例对课程是灾难性的」的可证明版本——decay 起步太早,把末段最好的数据浪费在已经趋零的步长上;
- 情形三(WSMD):刻意把 $T_0$ 缩到 $\Theta(M^{2/3})$,终态 LR 相应更大 → $\bar{\mathcal{L}}=\Theta(M^{-2/3}L^2)$,打破 $\Omega(L^2)$ 障碍。这从理论侧支撑了「适度 decay」缓解方案。
情形四:升序 + 恒定 LR + SWA(定理 4.1)
恒定 $\eta_0$ 下递推有闭式解 $\boldsymbol{w}_t=(1-\eta_0)^t\boldsymbol{w}_0+\eta_0\sum_{i=1}^{t}(1-\eta_0)^{t-i}\boldsymbol{x}^{(M-i+1)}$,即对历史样本做指数加权。对末 $n$ 个权重再取算术平均 $\bar{\boldsymbol{w}}_M=\frac{1}{n}\sum_{k=0}^{n-1}\boldsymbol{w}_{M-k}$。由于 $(1-\eta_0)^{M-i}$ 指数衰减,只有末 $n$ 个样本(即质量最高的 $n$ 个)对平均有非可忽略贡献。信号轴:
\[\bar{w}_M^{(1)} \approx \frac{1}{n}\sum_{j=1}^{n}\big[1-(1-\eta_0)^j\big]\,x_1^{(j)} = \Theta(nd)=\Theta\!\left(\frac{nL}{M}\right)\]噪声轴:$n$ 个独立噪声被 $\frac{1}{n}$ 平均,$\mathrm{Var}(\bar{w}_M^{(2)})=\Theta(L^2/n)$。取 $n=\Theta(M^{2/3})$,两轴均为 $\Theta(M^{-2/3}L^2)$,合并得 $\mathbb{E}[\mathcal{L}(\bar{\boldsymbol{w}}_M)]=\tilde{O}(M^{-2/3}L^2)$。
关键对比:SWA 用恒定 LR 保住了信号轴的大步长(不像 WSD 那样把步长衰减掉),同时用末段平均完成噪声轴降噪——它把 WSMD「适度 decay」在时间上做的事,改成在 checkpoint 空间上做。二者达到相同的 $M^{-2/3}$ 阶,但 SWA 无需精调 decay 起点,鲁棒性更高(与 §4.3 中 CMA「免调 decay」的实证优势呼应)。Figure 6 的四条模拟轨迹与上述四个结论一一对应:Uniform+WSD 因信号轴方差大而失败,Ascend+WSD 因 early-decay 推进不足而失败,Ascend+WSMD 与 Ascend+SWA 则沿信号轴推进充分而胜出。
理论局限:线性二次、二维、SGD;未刻画 Adam、Transformer 的表征学习,也未建模「质量随时间连续变化」之外的分布漂移。其价值在于机制隔离——用最小模型复现「为何 SWA/WSMD 能赢、实用 WSD 不能」这一定性分离,而非直接预测绝对 benchmark 分数。值得注意的是,$M^{2/3}$ 这一指数同时出现在最优 decay 窗口与最优平均 checkpoint 数中,提示「降噪强度应与训练步数次线性增长」,但论文未将其外推为可用的 scaling law(见 §7.3 开放问题)。
6. 核心实验结果深度解读
6.1 主预训练(Table 1)的逻辑链
实验结果支撑一条完整因果链:
- Cos + Uniform 差 → 说明评测与训练设定下 WSD 基线必要;
- WSD + Ascend ≈ WSD + Uniform → 标准 decay 抵消课程(论文核心 claim 的直接证据);
- Const + WA + Uniform < WSD + Uniform → WA alone 不够;
- Const + EMA/SMA + Ascend > WSD + Uniform → 课程与 WA 协同才是新 regime。
Core 上 SMA+Ascend 达 47.02(+0.81),MMLU、ARC-c 等单项亦有可见提升——不是单一任务偶然。
6.2 终态 LR 扫描(Figure 5)
将策略分为:
- Previous Focus Regime:Uniform、无 WA、终态 LR $10^{-5}$–$10^{-4}$(Llama 3、DCLM 常见);
- Optimal Regime:Ascend + moderate 终态 LR + EMA。
Mid-training 子图(Fig. 5b)上,蓝线(Uniform+WSD)随终态 LR 升高而恶化,橙线(Ascend+EMA)在 moderate 区间最优——两类 schedule 的最优 hyperparameter 不可共享。
6.3 消融实验
质量指标(PreSelect,Table 6):CMA/CDMA 仍优于 WSD+Ascend 基线;但升序 PreSelect 的验证 loss 可能高于 Uniform(Fig. 8),因训练集经 DCLM 过滤、验证集按 DCLM 高分选取,指标与验证目标不一致。
数据集(WebOrganizer 未过滤,Table 7):EMA+Ascend+Const 的 Core +1.87;高终态 LR 在「高质数据极稀疏」时可能更有利(与 mid-training 叙事一致)。
LR decay 函数(Table 4):1-sqrt 与 sqrt-cube 接近,均优于线性 decay。
6.4 大规模持续预训练(Appendix D)
| 项目 | 设定 |
|---|---|
| 模型 | 3.2B |
| Base 阶段 | 约 729B tokens,uniform 采样(DCLM 83.51% / Fineweb-C 12.60% / StarCoder 2.61% / MegaMath 1.28%) |
| 持续阶段 | >150B tokens(156.1B),四域 top-k 精选后混合 |
| Peak LR / batch | $1\times10^{-3}$ / 2048 |
| 课程 | 域内按各自质量指标排序 → 秩重标定 → 全局合并升序(Algorithm 2) |
| 基线 | Uniform + 末 84B tokens 线性 decay 至 $10^{-5}$ |
| CDMA | 多域课程 + decay 至 $3.67\times10^{-4}$ 后保持 + 末 6 checkpoint EMA(间隔约 1.67B tokens,$\alpha=0.2$) |
多域课程的工程难点与解法(Algorithm 2):跨域无法定义统一质量分(DCLM 用 fastText 文本分、StarCoder 用 GitHub star 数、MegaMath 用重复次数作 importance 代理),直接混排会破坏域配比。论文采用三步流水线:①域内升序排名 $r_A(x)$;②秩重标定把各域 rank 映射到同一全局刻度——
\[R_{\text{global}}(x_A) = r_A \times \frac{N_{\text{total}}}{N_A}\]其中 $N_A$ 为域 $A$ 样本数,$N_{\text{total}}$ 为全域总数。该归一化的精妙之处:rank 除以本域规模 $N_A$ 得到 $[0,1]$ 分位,再乘 $N_{\text{total}}$ 还原到全局刻度——于是不同域的同分位样本得到相近的全局秩,按 $R_{\text{global}}$ 升序合并后自动实现「①保留域内质量升序、②各域按 mixing ratio 比例交错、③全程域配比稳定」三性质。③全局交错排序。整个过程可用 Spark 一次性离线完成,适配工业级语料。
持续阶段 top-k 精选配比(Table 9):DCLM top-20%(53.77%)、Fineweb-C top-20%(15.34%)、StarCoder top-20%(24.95%)、MegaMath top-40%(5.94%)。注意代码/数学域占比偏低,是后文这两域增益受限的直接原因。
Table 10:Core Avg. 53.79 vs 52.70(+1.09%);ARC-C +3.39%,BoolQ +3.39%,CEval +1.29%(中文 Fineweb-C 验证了跨语言泛化),CSQA +1.07%,MMLU +0.44%;GSM8K 几乎不变(+0.08),MBPP −0.78%。代码/数学退化的两点归因:混合比例本就低,以及 GitHub star 数 / 重复次数这类粗糙指标无法准确刻画代码与数学质量——这恰好反向印证了全文主张:课程分数的「指标–目标对齐」与 LR/WA 同等重要。整体说明方法在更大模型、多域、持续预训练下仍有效,但域特异指标需更精细的课程分数设计。
6.5 反向课程与 schedule 交互(Table 11)
恒定 LR 下 Descend 明显差于 Ascend(Avg. 45.79 vs 49.37);Cosine 下差距缩小。解释 Wettig et al.「反向课程有时也有效」:低 peak LR + 强 decay 压缩了不同排序策略的可区分性,且指标噪声大;本文用更高 peak LR 与更一致验证,得到自洽的排序结论。
6.6 结果局限性(论文未充分展开部分)
- 全局排序成本:30B 规模可行,全量数 T token 需 Spark/分布式;A,A 分 phase 排序是实用折中,但是否损失全局最优未充分量化;
- 质量分数因果性:DCLM fastText 与下游任务相关但不等价;PreSelect 消融已显示指标–验证对齐的重要性;
- 与多 epoch / 重复数据:主实验偏单 epoch;现代 LLM 常 1 epoch,但 mid-training 续训多轮时课程是否需重排未讨论;
- 计算开销:EMA 需存末段 checkpoint,显存/存储开销增加,相对「纯 decay」有工程代价;
- 代码/数学域:大规模实验中 MBPP 略降,提示域特异分数 + 混合比例需与课程联合优化。
7. 关键结论与争议点
7.1 核心结论
- 实例级数据课程并非无效,而是在「为 uniform 优化的 LR decay」下被系统性压制;
- LR 是隐式样本权重,与升序课程在时间上冲突——这是机制层解释,不是单纯「调参没调好」;
- CMA/CDMA 开辟了新 regime:恒定或适度 LR + 权重平均 + 升序课程,可超过传统 WSD+Uniform;
- Mid-training 与多域持续预训练收益更突出,与工业「先广后精」流水线高度相关;
- 超参共设计:数据顺序、LR、WA 三者应在同一设计空间联合搜索。
7.2 与 DELT / Folding 的分歧与统一
| 维度 | DELT (FO) | 本文 |
|---|---|---|
| 核心手段 | 折叠排序,高质量样本分散到全程 | 升序 + 改 LR/WA,末段强吸收 |
| 对 LR decay | 隐含「规避」末段低 LR | 显式论证冲突并改 schedule |
| 恒定 LR 下 | FO 可能不如简单升序(DELT 文内) | 简单升序最优 |
| Cosine + decay | FO 可能略好于升序 | FO 仍不如 Uniform |
统一视角:二者都承认「末段高质量数据需要足够训练动力」。DELT 通过空间上重排(Folding)解决;本文通过优化 schedule 上解耦(WA/适度 decay)解决。在正确 LR regime 下,更简单的全局升序 + CMA 可能更优——工业落地需在「排序复杂度」与「schedule 改造」之间权衡。
7.3 开放问题
- 最优终态 LR 的 scaling law:$1/3$ peak 是否随模型规模、数据量变化?能否与 Li et al. (2025b) 的 hyperparameter scaling 律联合?
- 与 DELT LQS 评分结合:高质量样本定义若改为梯度一致性,升序是否更稳?
- Folding + CDMA:论文认为 Folding 常补偿错误 LR;若强制 CDMA,Folding 是否仍有独立收益?未做正交实验;
- WA 与分布式训练:大模型 checkpoint 平均的工程实践(在线 EMA vs 离线合并);
- 推理阶段:末段高 LR 是否影响 calibration——论文未评测困惑度以外的不确定性指标。
8. 与相关工作的关系
8.1 课程学习(Wettig、Kim & Lee、Zhang、Dai/DELT)
先前工作多在 cosine + 低 peak LR($\sim10^{-4}$) 下评估,报告 0.x% 量级增益或反向课程悖论。最典型的是 Wettig et al. (2024):低→高质量课程仅 +0.6%,却又观察到反向(降序)课程也能 +0.5% 的反直觉现象。本文给出两点归因:①低 peak LR 区间内 decay 过早压低有效 LR,压缩了升序与降序之间的可区分性,使二者差距被抹平;②质量指标本身缺乏自洽性,排序含噪。
本文用更高 peak LR($3\times10^{-3}$)与更一致的验证集,得到自洽的排序结论(Table 11):恒定 LR 下 Descend 显著差于 Ascend(Avg. 45.79 vs 49.37),Uniform 居中(47.80);cosine 下三者差距收窄(49.13 / 49.73 / 47.63)——正说明 decay 抹平了排序的可区分性,复现并解释了 Wettig 的悖论。本文最佳配置(Const+SMA)相对 Cos+Uniform 基线相对提升超 2.7%,远强于既往报告。
8.2 LR schedule(WSD、MiniCPM、Predictable Scale)
WSD 在 uniform 数据上接近最优且便于续训;本文不否定 WSD,而是主张 curriculum 场景应使用 WSMD 类 moderate decay 或 CMA。与 Tian et al. (WSM) 的 decay-free + merging 相比,本文强调 WA 与课程排序的协同,而非仅在 Uniform 上替代 decay。
8.3 模型平均(SWA、Llama 3、Li et al. 2025c)
既往结论:WA 与 LR decay 相当(略逊或持平)。本文发现:WA 的价值在课程下被低估——排序使末 checkpoint 质量更高,EMA 加权恰好放大这一效应。
8.4 数据策展 vs 数据 schedule
策展回答「训练什么」;schedule 回答「何时训练什么」。在策展已用尽的场景,schedule × optimizer 的共设计成为新的免费午餐——与 DELT 的「数据效力」维度正交,可叠加。
9. 总结
这篇工作把 LLM 预训练中一个长期存在的「失望现象」——按质量排序的数据课程几乎不涨点——重新归因于 学习率衰减与数据课程在时间轴上的结构性冲突,而不是质量分数无效。作者用隐式样本权重、river-valley 图景和二维可证明例子,把机制讲清楚;用 CMA/CDMA 和 moderate decay 给出可落地的修复,并在 1.5B/3.2B、mid-training、多域持续预训练上验证了稳健增益。
对实践者最值得带走的三条:
- 若已做或计划做实例级课程,请重新审视终态 LR——不要直接沿用 uniform 调出的 $10^{-5}$;
- 尝试末 checkpoint EMA($\alpha \approx 0.2$,6 个间隔)+ 升序,在 mid-training 第二阶段往往比再堆数据过滤更便宜;
- 评估课程学习时,必须同时报告 LR 与 WA 配置——否则结果可能只反映「错误 regime」下的阴性结论。
与 DELT 对照阅读尤佳:一个回答「怎么排」(Folding/LQS),一个回答「排了之后怎么训」(LR/WA)。在数据仍是大语言模型能力上限的当下,把数据顺序与优化动力学放在同一张设计图里,可能是比继续微调 cosine 终值更高效的一条路。